




A project in data mining
Without the knowledge of coding, you can train the model, predict the dataset class labels, feature selection, and much more using the weka tool.
Dataset details
Description:
Student engagement prediction database will be used in this project to predict the engagement level of students with learning resources. The predicted class label will show high or low based on the interaction of students with study material. The dataset contains 13 attributes including class attributes and almost 500 records.
It includes:
- Login: How many times does a student log in to the portal.
- Content Read: How many times a student read the study material content.
- Forum Reads: How many times a student read the problem/issue on community forum.
- Forum post: How many times a student posts the problem/issue on a community forum.
- Review: How many times a student reviews the quiz before submission.
- Lateness indicator: Is student submitting a late assignment. There are multiple lateness indicator attributes.
- Average assignment submission time: How many hours student takes to submit the assignment. There are multiple lateness indicator attributes.
- Engagement level: This is a class label that will show the level of student engagement to study materials based on previous attributes.
Source:
The Source of the dataset is from GitHub (open-source platform) and you can get this dataset from [here](github.com/Western-OC2-Lab/Student-Performa.. "link of dataset").
Problem type:
I want to predict class labels, so I will use classification because classification is used to predict the nominal value of the class attribute.
Techniques:
I will use the weka tool to classify to train the model and predict the class labels. I will also use feature selection to select the relevant attributes for model training.
Pratical Approach
Preprocessing:
Dataset is already preprocessed. There is no negative, null, or empty value. Class attribute label is nominal and contains H (high) or L (low) labels.
Classification:
I will use classification because classification is used to predict the nominal value of the class attributes. I will train the model using different algorithms and test options.
Here are some steps to perform classification:
- Load training data into weka.
- In classify tab, choose a tree and select the J48 algorithm.
- Select cross-validation (10 folds) in the test option.
- Select class attribute
- Start the process.
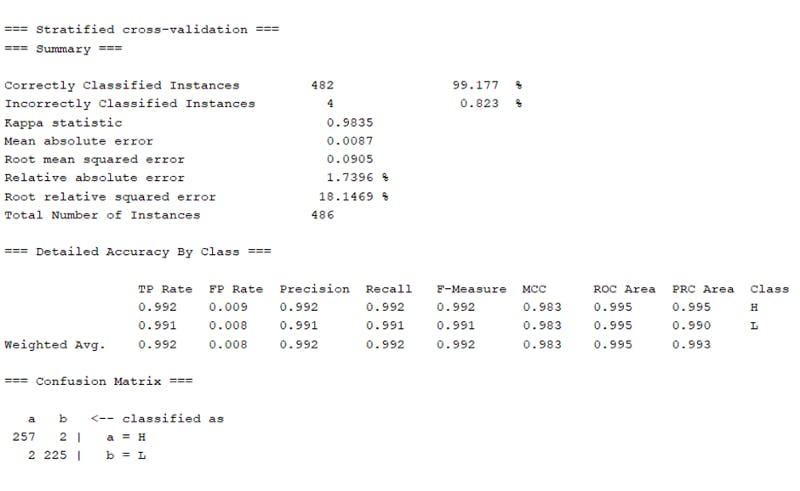
The result is showing that the dataset is 99% correctly classified. There are other details like total instances, root mean, absolute error, confusion matrix, accuracy details, etc.
Right-click on the result item and select “save the model” for test data label prediction.
Now, create the copy of training data, shuffle the order, and remove all the labels of the class attributes to check whether the trained model can predict class labels or not.
Here are some steps to perform prediction:
- In classify tab, choose supplied test data in test options.
- Load the test data file (without labels).
- Choose class attribute.
- Click on more options, choose Plain text in output prediction.
- Reevaluate the model on the current dataset.
- The result will show the predicted class labels.

The result is showing the predicted class labels as high or low based on the trained model.
Association rules:
Association rules are not applicable on this type of dataset and this feature is out of scope. Association rules are only applicable if the dataset contains itemset.
Feature selection:
The attribute selection task essentially consists in selecting a subset of originally available attributes to be subsequently used for model creation. For this purpose, I will use the select attribute tab to select the top 10 relevant attributes in the dataset that will be used in the training model.
Here are some steps to perform feature selection:
- Load training data into weka.
- In classify tab, choose info gain in attribute evaluator.
- Set number option to 10 in Ranker.
- Select cross-validation (10 folds) in test option.
- Select class attribute
- Start the process.
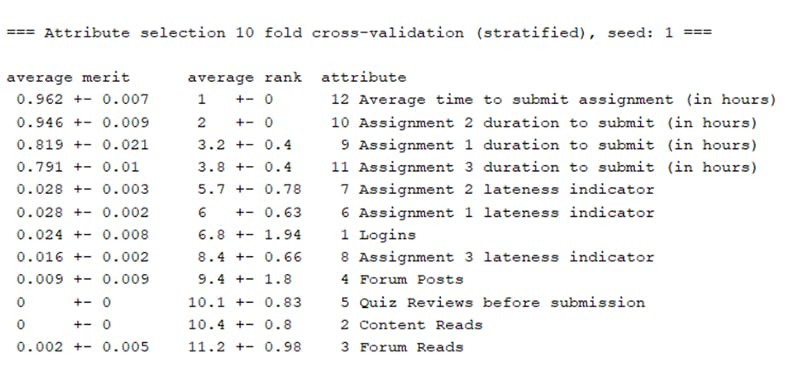
The result is showing relevant attributes which are necessary for model training. Attributes are short on the basis of average rank. Select top rank attributes for the training model. Class attributes will be mandatory.
[Mlearning.ai Submission Suggestions
How to become a writer on Mlearning.aimedium.com](https://medium.com/mlearning-ai/mlearning-ai-submission-suggestions-b51e2b130bfb "medium.com/mlearning-ai/mlearning-ai-submis..")